Artificial intelligence systems that interpret human behavior are rapidly transforming industries such as autonomous driving, smart surveillance, sports analytics, and healthcare monitoring. From detecting suspicious activities in security footage to analyzing player movements in sports, these systems rely heavily on well-annotated video datasets.
However, AI models cannot interpret human actions from raw video alone. They require structured, accurately labeled data that helps them learn how human activities unfold across time and space. This is where professional video annotation becomes essential.
According to a report by MarketsandMarkets, the AI training dataset market is projected to grow from $2.8 billion in 2024 to nearly $9.6 billion by 2029, reflecting the increasing demand for high-quality annotated datasets for machine learning systems. This growth highlights the importance of working with a trusted data annotation company that can deliver scalable and reliable training data.
In this guide, we explore how human actions are labeled in video datasets and how partnering with experts like Annotera can accelerate AI development.
Why Human Action Annotation Is Critical for AI Models
Human action recognition requires AI systems to analyze motion patterns across sequences of frames. Unlike image datasets, where labels describe static objects, video datasets capture continuous movement and interactions.
For example, a model must distinguish between actions such as:
- Walking versus running
- Picking up an object versus placing it down
- Waving versus pointing
To accomplish this, machine learning models rely on annotated datasets that clearly identify both what action is occurring and when it occurs within the video.
Large benchmark datasets demonstrate the scale required for effective training. The widely used Kinetics dataset contains hundreds of human action classes and hundreds of thousands of labeled video clips, enabling models to learn complex activity patterns.
As computer vision pioneer Fei-Fei Li famously said:
“Data is the new oil of the digital economy.”
For AI teams developing computer vision systems, high-quality labeled data is the foundation that determines model accuracy, reliability, and real-world performance. This is why many organizations partner with a specialized video annotation company to manage large-scale labeling projects.
Types of Human Actions Labeled in Video Datasets
Human action annotation can vary from simple movements to complex multi-person interactions. Understanding these categories helps define a structured annotation strategy.
Basic Physical Movements
These actions represent simple activities that are commonly used to train baseline action recognition models.
Examples include:
- Walking
- Running
- Sitting
- Standing
- Jumping
Even these seemingly simple actions require consistent labeling across thousands of frames to train robust AI models.
Human–Object Interactions
Many real-world applications require AI to understand how humans interact with objects.
Examples include:
- Opening doors
- Carrying packages
- Using mobile devices
- Driving vehicles
These annotations are particularly important for robotics, logistics automation, and retail analytics.
Human–Human Interactions
In surveillance, social analytics, and sports analysis, AI models must recognize interactions between people.
Examples include:
- Handshakes
- Conversations
- Passing objects
- Team sports actions
Such datasets often require multi-person tracking and contextual labeling.
Complex Behavioral Activities
Some AI applications require identifying complex or suspicious behaviors over longer video sequences.
Examples include:
- Workplace safety violations
- Crowd behavior analysis
- Security threat detection
These activities require temporal labeling across multiple frames and contextual understanding.
Key Annotation Techniques for Labeling Human Actions
Accurate human action labeling requires specialized video annotation techniques that capture both spatial and temporal information.
Bounding Box Annotation
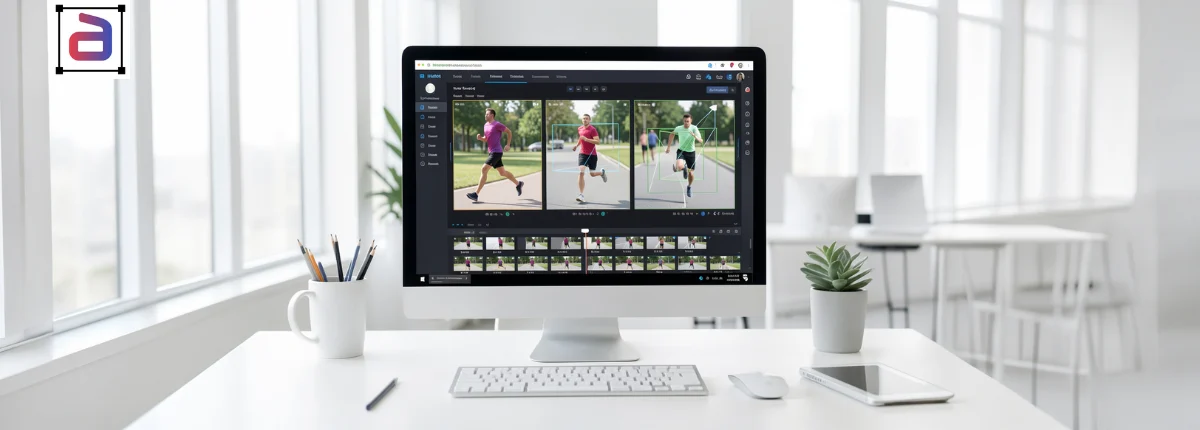
Bounding boxes are used to identify and track individuals within each frame of a video. Annotators draw rectangular boxes around a subject and assign action labels.
For example:
- Person walking
- Person carrying a bag
- Person entering a building
Bounding boxes help models learn how objects move within a scene.
Pose Estimation Annotation
Pose estimation focuses on identifying key body points such as shoulders, elbows, knees, and ankles.
By connecting these keypoints, AI models can analyze human posture and movement patterns. This technique is widely used in fitness tracking, sports analytics, and healthcare monitoring.
Temporal Segmentation
Human actions occur across time, not just individual frames. Temporal segmentation helps AI understand when an action begins and ends.
For example:
- Frames 30–100: Person running
- Frames 101–150: Person jumping
This enables models to recognize action transitions and sequence patterns.
Multi-Object Tracking
In many real-world scenarios, multiple individuals appear within the same video.
Multi-object tracking assigns a consistent ID to each person across frames, enabling AI systems to analyze movement trajectories and interactions.
Semantic Action Labeling
Semantic labels provide descriptive action tags that improve contextual understanding.
Examples include:
- “Person entering vehicle”
- “Person waving hand”
- “Person using laptop”
Fine-grained semantic labeling significantly enhances the accuracy of activity recognition models.
Step-by-Step Workflow for Human Action Video Annotation
Professional annotation teams follow structured workflows to ensure consistency and dataset reliability.
1. Dataset Preparation
Videos are reviewed, cleaned, and segmented into manageable clips. Frames are extracted at appropriate intervals depending on the application requirements.
2. Action Taxonomy Definition
A clear taxonomy of action categories is created before annotation begins.
For example:
- Walk
- Run
- Sit
- Pick up object
- Open door
This standardized labeling guide ensures consistency across the entire dataset.
3. Frame-Level Annotation
Annotators label individuals and objects across frames using bounding boxes, skeleton tracking, or polygon annotations.
4. Temporal Labeling
Actions are marked across specific time intervals, allowing AI models to learn how actions evolve over time.
5. Quality Assurance
Quality control teams verify annotation accuracy through:
- Multi-level review processes
- Automated validation checks
- Random sampling audits
These steps ensure high-precision training datasets.
Challenges in Labeling Human Actions
Despite advanced annotation tools, labeling video datasets presents several challenges.
Large Data Volumes
One minute of video can contain thousands of frames requiring annotation.
Occlusion Issues
People may be partially hidden by objects or other individuals.
Action Ambiguity
Similar actions may appear visually identical without contextual information.
Consistency Across Annotators
Large annotation teams must follow strict guidelines to maintain dataset uniformity.
To address these challenges, many organizations turn to data annotation outsourcing to access trained annotation teams and scalable infrastructure.
Why Businesses Choose Annotera for Video Annotation
Annotera is a trusted data annotation company that specializes in delivering high-quality datasets for AI and machine learning applications.
With over two decades of expertise in data services, Annotera supports organizations developing advanced computer vision models across industries including automotive, retail, healthcare, and security.
As a leading video annotation company, Annotera provides:
- Human action recognition annotation
- Pose estimation and keypoint labeling
- Multi-object tracking
- Temporal segmentation
- Behavioral activity labeling
Through secure and scalable video annotation outsourcing, Annotera enables businesses to process large video datasets efficiently while maintaining strict quality standards.
Our human-in-the-loop workflows ensure that every frame is reviewed and validated, producing AI-ready datasets that improve model performance and reduce training errors.
Accelerate Your AI Projects with Annotera
Building reliable AI models starts with accurate training data. Human action recognition models depend on precise video annotations that capture motion, interactions, and context.
Partnering with an experienced data annotation company like Annotera ensures that your datasets are labeled with the accuracy, consistency, and scalability required for modern AI development.
Looking to build high-quality video datasets for your AI models? Get in touch with Annotera today to explore our expert video annotation outsourcing solutions and transform your raw video data into AI-ready training datasets.

