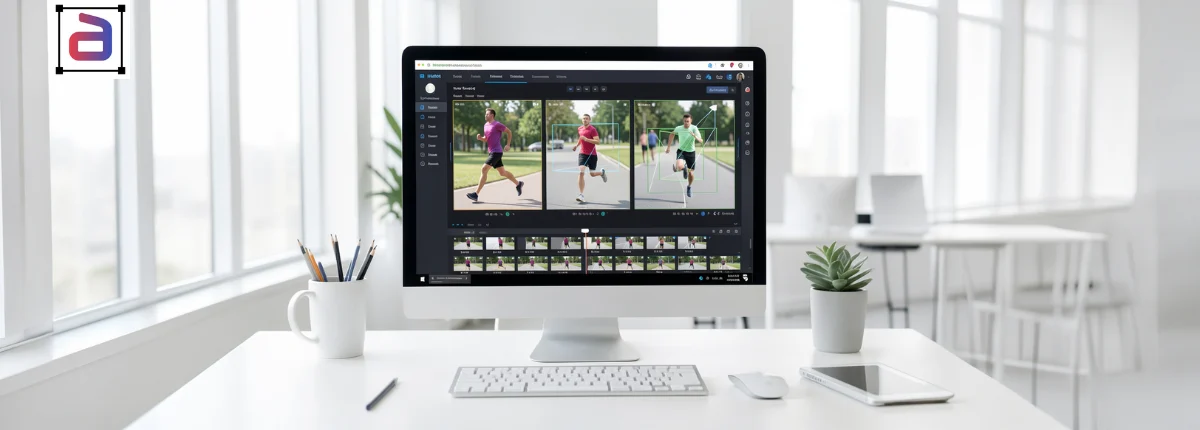
Introduction: Why Mask Choice Impacts Model Performance
In computer vision projects, annotation strategy is a foundational decision—not a downstream task. The type of mask you choose directly affects model accuracy, training time, infrastructure costs, and the ease with which your pipeline can scale. For data managers and ML Ops leaders, this choice often determines whether a project progresses smoothly or becomes bottlenecked by rework and ballooning annotation costs.Two approaches dominate most discussions: polygon labeling and segmentation masks. While both enable pixel-level understanding, they solve different problems and introduce different operational trade-offs. This polygon labeling guide explains how to evaluate both options pragmatically—based on data complexity, model goals, and production realities.
What Is Polygon Labeling?
Polygon labeling is a manual annotation method where annotators draw multi-point shapes that closely follow an object’s boundaries. Unlike bounding boxes, polygons adapt to irregular contours, making them well suited for objects that do not fit clean geometric shapes.
From a data operations perspective, polygon labeling offers:
- High boundary precision without labeling every pixel
- Strong human control over edge cases and ambiguity
- Faster turnaround compared to dense segmentation
- Lower QA overhead for many real-world datasets
Polygon labeling is commonly used when accuracy matters more than full-scene density and when annotation efficiency is a key constraint.
What Is Segmentation?
Segmentation assigns a class label to every pixel in an image or video frame. Depending on the task, this may take the form of semantic, instance, or panoptic segmentation. The result is a dense mask that provides complete visual context for a scene.
While segmentation delivers rich spatial information, it also introduces higher complexity:
- Greater annotation time per frame
- Increased tooling and computing requirements
- More intensive quality assurance
Segmentation is powerful, but it is not always the most practical starting point—especially for teams managing cost, timelines, and evolving model requirements.
Polygon Labeling vs. Segmentation: A Practical Comparison
Accuracy and Boundary Control
Polygon labeling excels at capturing precise object boundaries where edge accuracy matters most. Segmentation provides full-scene coverage but may introduce noise when boundaries are ambiguous or visually dense.
Annotation Time and Cost
Polygon labeling is typically faster and more cost-efficient. Segmentation requires pixel-level attention across entire frames, significantly increasing labeling and review effort.
Scalability and Maintenance
Polygon labelling guide scale more predictably for growing datasets. Segmentation often requires automation or model-assisted labeling to remain operationally viable at scale.
Model Training Implications
Polygon labels are frequently used to bootstrap segmentation models or support instance-level learning. Segmentation is better suited for tasks that demand dense contextual awareness across the entire image.
When Polygon Labeling Is the Right Choice
Polygon labeling is a strong fit when:
- Objects have irregular or non-rectangular shapes
- Only specific classes require high precision
- Dataset sizes are moderate or evolving
- Human judgment is needed for ambiguous cases
- Budgets or timelines require efficiency
Common examples include medical imaging, agricultural AI, retail product recognition, and industrial inspection workflows.
When Segmentation Makes More Sense
Segmentation becomes the better option when:
- Every pixel contributes meaningfully to the model
- Background context is critical to predictions
- Large-scale automation is available
- Long-term reuse of dense masks is expected
Use cases such as autonomous driving, satellite imagery, and urban scene understanding often fall into this category.
Hybrid Approaches in Modern ML Pipelines
Many teams do not choose between polygon labeling and segmentation—they combine them. A common strategy is to start with polygon labeling to establish high-quality ground truth, then use those labels to train or assist segmentation models.
Hybrid approaches help teams:
- Control early-stage costs
- Improve annotation consistency
- Transition smoothly from pilot to production
How Annotation Services Help Data Managers Decide
Experienced annotation service providers support data managers by running pilots, benchmarking accuracy versus cost, and designing annotation strategies that evolve alongside models. This reduces the risk of over-investing in dense labeling before it is truly needed.
Annotera’s Guidance on Polygon Labeling and Segmentation
Annotera works with data teams to select the right masking strategy based on real operational constraints—not theoretical ideals. Support includes:
- Advisory input on polygon vs. segmentation trade-offs
- Custom annotation guidelines
- Scalable human-in-the-loop workflows
- Dataset-agnostic services with full data ownership
- Transparent quality and consistency metrics
Conclusion: Choose the Mask That Fits the Model
There is no universally correct annotation method. The right choice depends on your data complexity, model objectives, and operational realities.
This polygon labeling guide shows how thoughtful mask selection can reduce rework, control costs, and improve downstream model performance. With the right strategy and an experienced annotation partner, data teams can move from experimentation to production with confidence.
Unsure Whether Polygon Labeling Or Segmentation Is Right For Your Project?
Annotera helps data teams evaluate trade-offs, run pilots, and implement annotation strategies that scale with confidence. Talk to Annotera to align your labeling approach with your model goals, budget, and timelines.