
How Annotera Supports Semantic Annotation for RAG
Annotera provides semantic annotation services for RAG systems across healthcare, finance, legal, and technology domains. Our teams design semantic taxonomies aligned with your domain, label entities and relationships at scale, compute inter-annotator agreement to ensure quality, and deliver structured knowledge assets ready for RAG deployment. We handle domain-specific disambiguation problems so your RAG system retrieves results correctly.
Conclusion
Semantic annotation is the bridge between raw text and structured knowledge. It resolves ambiguity, establishes relationships, and enables RAG systems to retrieve with meaning rather than just matching keywords. Organizations that invest in high-quality semantic annotation build RAG systems that users can trust.
Ready to build a RAG system that understands meaning? Partner with Annotera for expert-led semantic text annotation that powers accurate, grounded retrieval and generation.
Building a RAG system that needs domain-accurate retrieval? Annotera provides text annotation services including semantic chunking, entity labeling, and relevance grading for RAG training datasets. Start with a free pilot.
It is worth also looking at measuring RAG performance.
This connects closely with structuring knowledge bases for enterprise RAG.
A closely related read: Using Generative AI to Pre-Annotate Text: A Guide To Human-in-the-Loop Workflows.
Challenges in Semantic Annotation at Scale
Semantic annotation requires judgment. Annotators must understand context, recognize which meaning of an ambiguous word is intended, and label relationships between entities. That judgment is harder to scale than simple keyword tagging. A team of 100 annotators tagging entities might achieve high agreement. A team of 100 annotators resolving domain-specific semantic relationships might achieve 0.65 Cohen’s kappa on the first pass, requiring guideline refinement and re-annotation.
The solution is careful guideline design. Document examples of each label type. Show borderline cases and the correct interpretation. Compute inter-annotator agreement on a sample before scaling. If agreement is below 0.75, revise the guidelines and try again. Once agreement is high, the team can annotate the full dataset with confidence.
How Annotera Supports Semantic Annotation for RAG
Annotera provides semantic annotation services for RAG systems across healthcare, finance, legal, and technology domains. Our teams design semantic taxonomies aligned with your domain, label entities and relationships at scale, compute inter-annotator agreement to ensure quality, and deliver structured knowledge assets ready for RAG deployment. We handle domain-specific disambiguation problems so your RAG system retrieves results correctly.
Conclusion
Semantic annotation is the bridge between raw text and structured knowledge. It resolves ambiguity, establishes relationships, and enables RAG systems to retrieve with meaning rather than just matching keywords. Organizations that invest in high-quality semantic annotation build RAG systems that users can trust.
Ready to build a RAG system that understands meaning? Partner with Annotera for expert-led semantic text annotation that powers accurate, grounded retrieval and generation.
Building a RAG system that needs domain-accurate retrieval? Annotera provides text annotation services including semantic chunking, entity labeling, and relevance grading for RAG training datasets. Start with a free pilot.
It is worth also looking at measuring RAG performance.
This connects closely with structuring knowledge bases for enterprise RAG.
A closely related read: Using Generative AI to Pre-Annotate Text: A Guide To Human-in-the-Loop Workflows.
Building Knowledge Graphs Through Semantic Annotation
Semantic annotation feeds into knowledge graph construction. A knowledge graph is a database of entities and relationships — Merck is an Organization, Merck’s headquarters are in Whitehouse Station, Merck produces Keytruda (a drug). When text is semantically annotated, those entities and relationships can be extracted and linked into a graph. A RAG system with access to a knowledge graph can answer complex questions by traversing relationships among entities. For example: “What companies produce cancer drugs?” The system finds entities of type Drug with the property treats_condition=cancer, then traces produced_by relationships to identify the companies.
Challenges in Semantic Annotation at Scale
Semantic annotation requires judgment. Annotators must understand context, recognize which meaning of an ambiguous word is intended, and label relationships between entities. That judgment is harder to scale than simple keyword tagging. A team of 100 annotators tagging entities might achieve high agreement. A team of 100 annotators resolving domain-specific semantic relationships might achieve 0.65 Cohen’s kappa on the first pass, requiring guideline refinement and re-annotation.
The solution is careful guideline design. Document examples of each label type. Show borderline cases and the correct interpretation. Compute inter-annotator agreement on a sample before scaling. If agreement is below 0.75, revise the guidelines and try again. Once agreement is high, the team can annotate the full dataset with confidence.
How Annotera Supports Semantic Annotation for RAG
Annotera provides semantic annotation services for RAG systems across healthcare, finance, legal, and technology domains. Our teams design semantic taxonomies aligned with your domain, label entities and relationships at scale, compute inter-annotator agreement to ensure quality, and deliver structured knowledge assets ready for RAG deployment. We handle domain-specific disambiguation problems so your RAG system retrieves results correctly.
Conclusion
Semantic annotation is the bridge between raw text and structured knowledge. It resolves ambiguity, establishes relationships, and enables RAG systems to retrieve with meaning rather than just matching keywords. Organizations that invest in high-quality semantic annotation build RAG systems that users can trust.
Ready to build a RAG system that understands meaning? Partner with Annotera for expert-led semantic text annotation that powers accurate, grounded retrieval and generation.
Building a RAG system that needs domain-accurate retrieval? Annotera provides text annotation services including semantic chunking, entity labeling, and relevance grading for RAG training datasets. Start with a free pilot.
It is worth also looking at measuring RAG performance.
This connects closely with structuring knowledge bases for enterprise RAG.
A closely related read: Using Generative AI to Pre-Annotate Text: A Guide To Human-in-the-Loop Workflows.
Multi-Level Semantic Labeling for RAG
Effective semantic annotation for RAG uses multiple layers of labeling, each capturing different aspects of meaning. Level 1: Named entities (people, organizations, locations, products, dates). Level 2: Entity relationships (X is CEO of Y, X acquired Y, X is located in Y). Level 3: Intent or topic (this document is about product launches, acquisition deals, scientific research). Level 4: Sentiment and confidence (this claim is stated as fact vs opinion, with high confidence vs speculation).
A RAG system that receives all four levels can retrieve with far greater precision than one working from just entities. A query about “companies acquired by Amazon” can filter for relationships (acquired_by), filter for the entity (Amazon), and ignore documents that mention both words but in unrelated contexts.
Building Knowledge Graphs Through Semantic Annotation
Semantic annotation feeds into knowledge graph construction. A knowledge graph is a database of entities and relationships — Merck is an Organization, Merck’s headquarters are in Whitehouse Station, Merck produces Keytruda (a drug). When text is semantically annotated, those entities and relationships can be extracted and linked into a graph. A RAG system with access to a knowledge graph can answer complex questions by traversing relationships among entities. For example: “What companies produce cancer drugs?” The system finds entities of type Drug with the property treats_condition=cancer, then traces produced_by relationships to identify the companies.
Challenges in Semantic Annotation at Scale
Semantic annotation requires judgment. Annotators must understand context, recognize which meaning of an ambiguous word is intended, and label relationships between entities. That judgment is harder to scale than simple keyword tagging. A team of 100 annotators tagging entities might achieve high agreement. A team of 100 annotators resolving domain-specific semantic relationships might achieve 0.65 Cohen’s kappa on the first pass, requiring guideline refinement and re-annotation.
The solution is careful guideline design. Document examples of each label type. Show borderline cases and the correct interpretation. Compute inter-annotator agreement on a sample before scaling. If agreement is below 0.75, revise the guidelines and try again. Once agreement is high, the team can annotate the full dataset with confidence.
How Annotera Supports Semantic Annotation for RAG
Annotera provides semantic annotation services for RAG systems across healthcare, finance, legal, and technology domains. Our teams design semantic taxonomies aligned with your domain, label entities and relationships at scale, compute inter-annotator agreement to ensure quality, and deliver structured knowledge assets ready for RAG deployment. We handle domain-specific disambiguation problems so your RAG system retrieves results correctly.
Conclusion
Semantic annotation is the bridge between raw text and structured knowledge. It resolves ambiguity, establishes relationships, and enables RAG systems to retrieve with meaning rather than just matching keywords. Organizations that invest in high-quality semantic annotation build RAG systems that users can trust.
Ready to build a RAG system that understands meaning? Partner with Annotera for expert-led semantic text annotation that powers accurate, grounded retrieval and generation.
Building a RAG system that needs domain-accurate retrieval? Annotera provides text annotation services including semantic chunking, entity labeling, and relevance grading for RAG training datasets. Start with a free pilot.
It is worth also looking at measuring RAG performance.
This connects closely with structuring knowledge bases for enterprise RAG.
A closely related read: Using Generative AI to Pre-Annotate Text: A Guide To Human-in-the-Loop Workflows.
Retrieval-Augmented Generation systems retrieve context before generating answers. But retrieving the right context depends entirely on whether the system understands its meaning. Semantic text annotation is what teaches it. By labeling text with meaning, relationships, and domain-specific intent — not just keywords — annotation creates the structured knowledge that RAG systems need to retrieve accurately and generate answers that are grounded in fact.
This guide covers what semantic annotation is, why it matters for RAG specifically, the disambiguation problem that makes it necessary, and how to structure annotations so that a RAG system retrieves the right information reliably.
Key Points
- Semantic annotation teaches RAG systems the meaning behind text, not just keyword presence — the difference between retrieving relevant context and retrieving superficially similar text.
- Entity linking in RAG annotation connects mentions to knowledge base entries, enabling the retrieval layer to distinguish a company name from a person with the same name.
- Poor semantic annotation causes RAG systems to retrieve plausible-sounding but wrong context, making the generator more confident in incorrect answers.
- The quality of a RAG system’s factual grounding is bounded by the quality of semantic annotation in its knowledge base — retrieval cannot fix what annotation missed.
Table of Contents
What Semantic Text Annotation Is
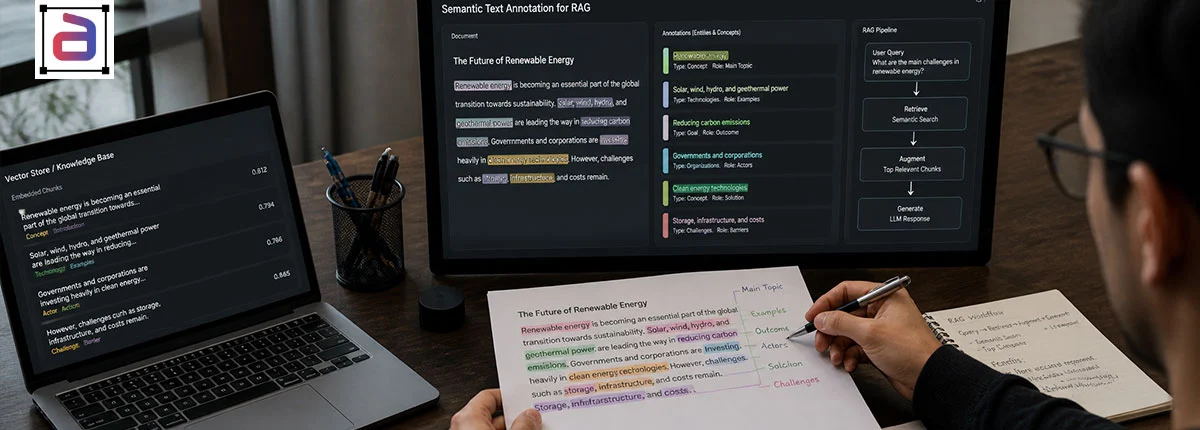
Semantic annotation labels text with meaning. Not just keywords. Not just parts of speech. But the real-world concepts the text refers to, how those concepts relate to each other, and what domain or context they belong in. Semantic annotation answers the question: What does this text actually mean, not just what words does it contain?
The classic example: “Amazon” can refer to the company, the rainforest, or the river. Keyword-based search cannot distinguish between them. Semantic annotation labels each occurrence with its meaning: “Amazon” as “Organization” vs “Natural_Feature” vs “Geographic_Location.” A RAG system trained on semantically annotated data retrieves documents about the right Amazon for the user’s query.
Semantic annotation includes several overlapping tasks. Named Entity Recognition labels people, organizations, and locations. Relationship extraction identifies connections such as “CEO_of” or “located_in.” Intent labeling captures what the user or text is trying to do. Sentiment analysis identifies positive, negative, and neutral. Topic classification assigns a domain or subject area. Together, these annotations turn raw text into structured knowledge.
Why RAG Systems Need Semantic Annotation
A RAG system has two jobs: retrieve the right context, then generate an answer grounded in that context. Semantic annotation directly improves the retrieval job. Without it, retrieval is purely keyword-based, which fails on the ambiguity problem.
The retrieval failure case. A user queries a healthcare knowledge base: “What does Amazon recommend for diabetes management?” The system keyword-matches on “Amazon” and retrieves documents about the Amazon rainforest and its medicinal plants. A semantically annotated knowledge base distinguishes the company Amazon (which has no diabetes recommendations) from geographic references, so retrieval stays focused on relevant sources. The generated answer is grounded in facts rather than in mismatched documents.
The hallucination reduction case. A RAG system retrieves documents, but without semantic labeling, it does not know what role each piece of information plays. A document might mention “Johnson” as a company, a person, or a place. Without semantic relationships marked, the retriever cannot distinguish between “Johnson & Johnson acquired X” and “Dr. Johnson recommends Y.” When the generator reads the retrieved context, it may conflate them. Semantic annotation prevents that by making the relationships explicit: Johnson-Company vs Johnson-Person, each with its own relationships and attributes.
The Disambiguation Problem
Why is semantic annotation necessary? Because language is ambiguous, computers need help resolving that ambiguity. A retrieval system that does not understand meaning cannot handle polysemy (one word, multiple meanings), metonymy (referring to a thing by the name of something related to it), or context-dependent interpretation.
Polysemy example. “The bank approved the loan.” Does “bank” refer to a financial institution or a riverbank? Context makes it clear to humans. A semantic annotation labels “bank” as “FinancialInstitution” rather than “GeographicFeature,” so a RAG system retrieving documents about riverbank erosion does not also pull up financial documents.
Metonymy example. “Merck announced a new drug.” Merck, the company, made an announcement. Semantic annotation labels “Merck” as an Organization with the property “announces_products,” so the retriever understands that queries about drug announcements should retrieve Merck documents, not documents that merely mention Merck’s location or CEO.
Context-dependent example. “The system was updated last week.” In a software documentation context, “system” means the software system. In a healthcare context, it might mean a body system. Semantic annotation includes the domain or context, so “system” in a software manual is tagged as “SoftwareSystem,” and retrieval for software queries does not pull healthcare documents.
Resolving ambiguity at annotation time — when a human understands context — is far easier and more reliable than expecting the retriever to resolve it in production.
Multi-Level Semantic Labeling for RAG
Effective semantic annotation for RAG uses multiple layers of labeling, each capturing different aspects of meaning. Level 1: Named entities (people, organizations, locations, products, dates). Level 2: Entity relationships (X is CEO of Y, X acquired Y, X is located in Y). Level 3: Intent or topic (this document is about product launches, acquisition deals, scientific research). Level 4: Sentiment and confidence (this claim is stated as fact vs opinion, with high confidence vs speculation).
A RAG system that receives all four levels can retrieve with far greater precision than one working from just entities. A query about “companies acquired by Amazon” can filter for relationships (acquired_by), filter for the entity (Amazon), and ignore documents that mention both words but in unrelated contexts.
Building Knowledge Graphs Through Semantic Annotation
Semantic annotation feeds into knowledge graph construction. A knowledge graph is a database of entities and relationships — Merck is an Organization, Merck’s headquarters are in Whitehouse Station, Merck produces Keytruda (a drug). When text is semantically annotated, those entities and relationships can be extracted and linked into a graph. A RAG system with access to a knowledge graph can answer complex questions by traversing relationships among entities. For example: “What companies produce cancer drugs?” The system finds entities of type Drug with the property treats_condition=cancer, then traces produced_by relationships to identify the companies.
Challenges in Semantic Annotation at Scale
Semantic annotation requires judgment. Annotators must understand context, recognize which meaning of an ambiguous word is intended, and label relationships between entities. That judgment is harder to scale than simple keyword tagging. A team of 100 annotators tagging entities might achieve high agreement. A team of 100 annotators resolving domain-specific semantic relationships might achieve 0.65 Cohen’s kappa on the first pass, requiring guideline refinement and re-annotation.
The solution is careful guideline design. Document examples of each label type. Show borderline cases and the correct interpretation. Compute inter-annotator agreement on a sample before scaling. If agreement is below 0.75, revise the guidelines and try again. Once agreement is high, the team can annotate the full dataset with confidence.
How Annotera Supports Semantic Annotation for RAG
Annotera provides semantic annotation services for RAG systems across healthcare, finance, legal, and technology domains. Our teams design semantic taxonomies aligned with your domain, label entities and relationships at scale, compute inter-annotator agreement to ensure quality, and deliver structured knowledge assets ready for RAG deployment. We handle domain-specific disambiguation problems so your RAG system retrieves results correctly.
Conclusion
Semantic annotation is the bridge between raw text and structured knowledge. It resolves ambiguity, establishes relationships, and enables RAG systems to retrieve with meaning rather than just matching keywords. Organizations that invest in high-quality semantic annotation build RAG systems that users can trust.
Ready to build a RAG system that understands meaning? Partner with Annotera for expert-led semantic text annotation that powers accurate, grounded retrieval and generation.
Building a RAG system that needs domain-accurate retrieval? Annotera provides text annotation services including semantic chunking, entity labeling, and relevance grading for RAG training datasets. Start with a free pilot.
It is worth also looking at measuring RAG performance.
This connects closely with structuring knowledge bases for enterprise RAG.
A closely related read: Using Generative AI to Pre-Annotate Text: A Guide To Human-in-the-Loop Workflows.


