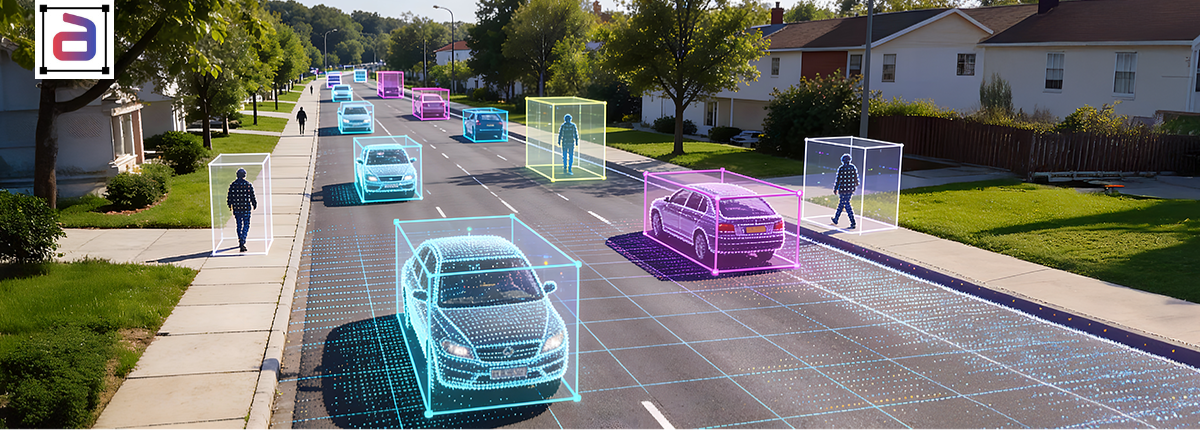
Autonomous vehicles operate through sensor fusion: combining LiDAR point clouds, camera images, radar returns, and depth sensor data into a single world model. The technical challenge is acute. Each sensor modality represents the same physical object in incompatible formats. LiDAR produces sparse 3D coordinates (typically 64,000–200,000 points per frame) with no color or semantic information. Cameras produce dense pixel grids (1920×1200 or higher) with no direct depth beyond stereo reconstruction. Radar produces velocity vectors with coarse spatial resolution but robust velocity estimation. Without precise alignment, the fusion network cannot learn robust object detection, tracking, or trajectory prediction.
LiDAR cuboid annotation solves this alignment problem by creating explicit cross-modal ground truth. A cuboid—a 3D bounding box with position, dimensions, and orientation—serves as the spatial anchor that allows the model to register point cloud regions to image pixels to radar returns. This guide covers the technical depth: how sparse point clouds constrain labeling decisions, why temporal synchronization breaks fusion models when done wrong, how to handle occlusion consistently, and what quality metrics actually predict real-world fusion performance.
Table of Contents
The Sensor Fusion Alignment Problem
Imagine an autonomous vehicle traveling 30 mph, encountering another car 40 meters ahead. The LiDAR scanner (128 channels) fires at 10 Hz, capturing a point cloud every 100 milliseconds. At 40 meters, the target car’s silhouette spans roughly 5 meters horizontally. Point density at that range is sparse—approximately 60–80 points covering the car’s outline. The camera simultaneously captures a 1920×1200 image at 30 Hz. The car’s bounding box in the image is roughly 150×90 pixels. Radar reports the car’s velocity as 25 mph approaching, with velocity uncertainty of ±2 mph.
The fusion model must predict that the sparse point cloud region (60–80 points), the pixel region (150×90 pixels), and the radar velocity reading (25 mph) all describe the same object. Without explicit ground truth alignment, the model infers this correspondence from raw sensor streams. The signal is weak because modalities are so different. A camera-only model learns visual features. A LiDAR-only model learns spatial geometry. A radar-only model learns kinematics. Fusing them requires learning cross-modal relationships: pixel A corresponds to point B, which corresponds to velocity C. This learning is exponentially harder without explicit correspondence labels.
Cuboid annotation provides explicit correspondence. A cuboid is defined by 7 parameters: position (x, y, z in vehicle frame), dimensions (length, width, height), and yaw (rotation around vertical axis). Placing a cuboid at (x=40m, y=0, z=0) with dimensions (4.5m, 2m, 1.5m) and yaw=0° maps that cuboid to: (1) the specific 60–80 points in the cloud, (2) the 150×90 pixel region, and (3) the 25 mph velocity reading at that timestamp. The fusion model learns these mappings from millions of annotated examples.
Why 3D Annotation Is Harder Than 2D
2D bounding box annotation on images is visually straightforward: identify the object’s leftmost, rightmost, topmost, and bottommost pixels, then draw a rectangle. Ambiguity is low. The task is bounded by image resolution. Humans are good at this task.
3D cuboid annotation on point clouds is cognitively harder because the annotator cannot directly see the object’s full 3D structure. The point cloud is sparse. A car 50 meters away yields only 10–20 points. The annotator must infer: (1) which points belong to the car (cluster membership), (2) the car’s dimensions (length, width, height in meters), (3) the car’s 3D position (x, y, z coordinates), and (4) the car’s yaw rotation (which direction the car faces). The annotator performs these inferences using synchronized camera imagery (providing visual context) and sometimes previous frames (providing velocity estimates to disambiguate orientation).
LiDAR cuboid annotation is the foundation of sensor fusion perception. It creates explicit cross-modal ground truth, enabling models to learn deep correspondences among point clouds, camera images, and radar returns. The technical challenges are real: sparse point clouds constrain what annotators can infer, temporal synchronization across sensors introduces subtle errors, and rotation estimation is inherently ambiguous without strong visual cues.
Teams that treat cuboid annotation as a straightforward labeling task discover that their fusion models fail in edge cases. Teams that invest upfront in occlusion policies, dimension priors, yaw templates, and rigorous quality control build perception systems that work reliably at scale. Building sensor fusion systems that perform in the real world? Partner with Annotera for LiDAR cuboid annotation that handles sparse data, temporal synchronization, occlusion, and rotation accuracy at scale.



